作者nikolas (你花多少時間?)
看板Python
標題Fw: [轉錄] 用機器學習判定紅樓夢後40回是否曹雪芹
時間Thu Jul 7 14:18:22 2016
※ [本文轉錄自 Redology 看板 #1NVBC1CP ]
作者: mited (太郎) 看板: Redology
標題: [轉錄] 用機器學習判定紅樓夢後40回是否曹雪芹
時間: Wed Jul 6 15:27:56 2016
張愛玲名言:「紅樓夢看到八十回後,一個個人物都語言無味,面目可憎起來」
對岸有人用電腦運算80回前後用詞習慣的改變
雖然特徵選取方式尚有可議之處
但也呈現出值得參考的觀點
知乎:用機器學習判定紅樓夢後40回是否曹雪芹所寫
https://zhuanlan.zhihu.com/p/21421723
作者:黎晨
作為一個從沒看過紅樓夢的人,我的大致思路是這樣的:
1.受到全職獵人裡蟻王破解會長無敵招數的啟發,每個人的寫作都有些小習慣,雖然文章
前後說的內容會有差別,但是這些用詞的小習慣不容易改變;
2.用開源的分詞工具把全書分詞(python的jieba分詞),然後統計詞頻。把出現頻次超
過100次的詞語找出來,人工去掉一些可能因為文章內容造成前後出現不一致的人名、
地名
3.然後每一章按照2中的詞頻表,看這一章中出現這些詞語的頻次;
4.前80回、後40回各選15回作為機器學習的數據,讓機器學習這些章節的用詞特點,然後
推算其他章節的用詞特點是屬於前80回呢、還是後40回;
5.如果機器根據這些用詞特徵推算的是否屬於後40回的結果跟實際的結果吻合,那麼就說
明後40回的寫作風格跟前80回有很大不同,很可能是兩個人寫的;
好了,下面我盡量少涉及數學跟編程的知識,來一步步解讀機器學習是怎麼完成這個問題
的。
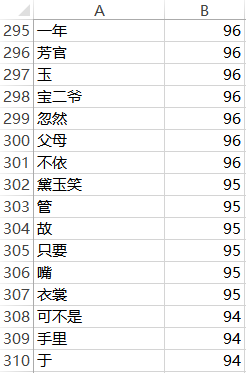
生成全書的詞頻表
https://pic4.zhimg.com/86db71e47e3cbd6091906d50c61ab967_b.png
我截取了其中一段的詞頻表。像寶二爺、黛玉笑這種涉及人物的詞語,可能前面戲份多、
後面戲份少,所以就不選它們作為用詞習慣的特徵,而像忽然、故、只要、可不是這種承
接性質的碎詞,就不太容易會受情節的影響,所以適合選出來作為用詞習慣的特徵。
最終,我按照出現從多到少排序,選擇了278個詞作為機器學習的用詞習慣。
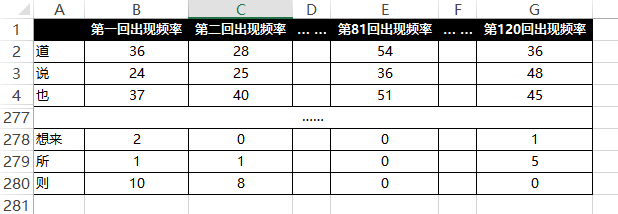
將120回的詞頻進行統計
接下來我把每一回出現這278個詞的頻次統計出來,得到我們給機器學習的樣本。這個樣
本的樣子大概是這樣的:
https://pic1.zhimg.com/999d0b7e34e5df4f9f00a6bdffec245c_b.png
比如以B行2列舉例,說明在第一回裡面「道」這個動詞,出現了36次。
通常我們在進行複雜的事情前,喜歡先簡化問題,或者給自己一些直觀的圖表,以便了解
問題。機器學習也是一樣的。
我嘗試著在圖上把前80回和後40回習慣用詞出現的頻次畫出來。以第一回為例,x1坐標代
表「道」出現多少次,x2坐標代表「說」出現多少次,x3坐標代表「也」出現多少次
......x280坐標代表「則」出現多少次。
什麼?超過三維了,那人類的大腦可是沒辦法理解的啊。
沒關係,當我們用燈光照射一個立體的圖時,平面會有它的影子。這個影子雖然沒有立體
圖的信息這麼豐富,不過我們看影子還是可以猜出來大致的樣子。對於高緯度的問題,我
們也可以用投影的方式來降低緯度。
雖然信息損失了不少,不過能給我們一個直觀的感受。
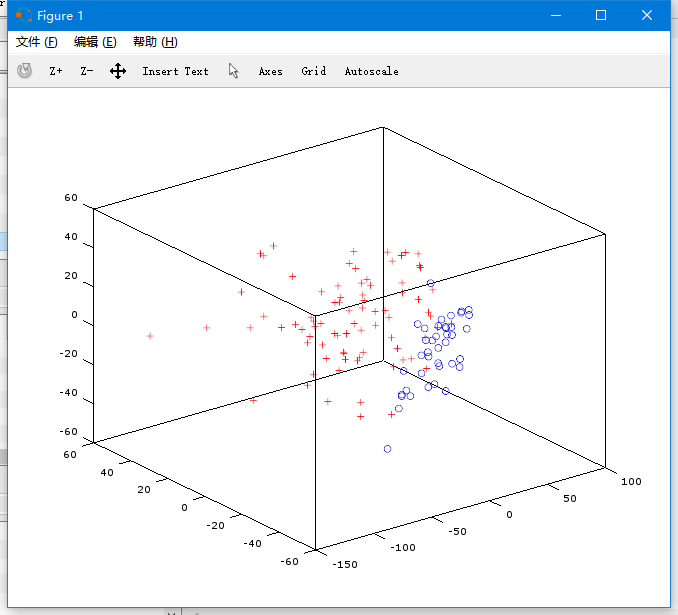
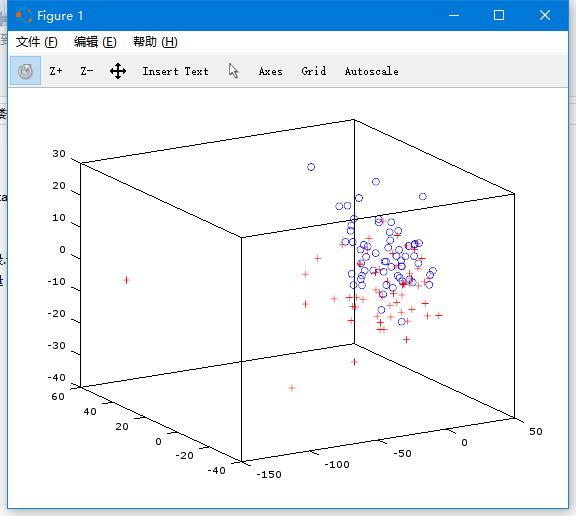
https://pic3.zhimg.com/d89993509cfb2ea46e2fead27df7616e_b.png
這個是120個章節的用詞習慣從278緯降到3維以後的圖,紅色+的點是前80回,藍色o的點
是後40回。
從這個圖可以直觀地看到,確實在用詞習慣上有明顯的區別。就算我們沒有機器學習工具
的幫忙,也可以大膽猜測後40回是出自於另外一個人了。
下面我們用機器學習來看精確一點的判斷。
機器學習
通過課程我大致了解了SVM的原理和簡化版問題的算法實現,不過對於復雜問題我還是沒
這個編碼能力的。於是用python的scikit庫來幫助我來完成這個預測。
算法的步驟很簡單,前80回、後40回各選15個來餵給機器學習它們的特點,然後把剩下的
章節輸入給機器,問它們屬於前80還是後40。
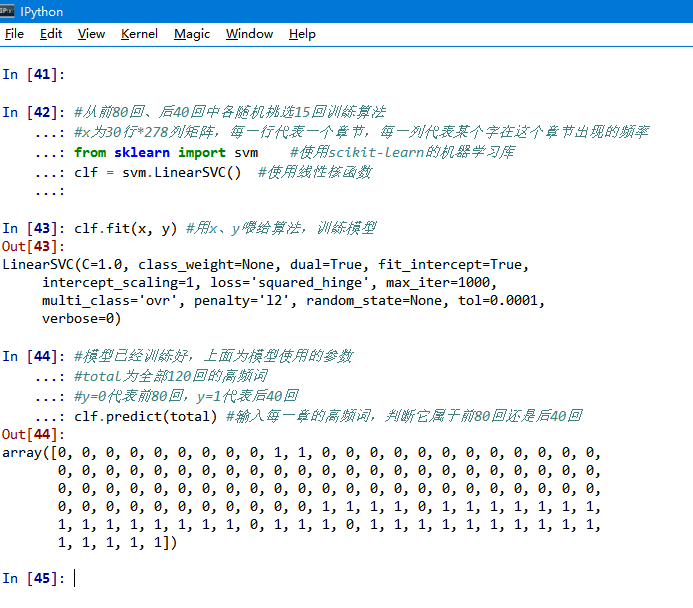
https://pic4.zhimg.com/8269c925992144fa4ab1cc18be09d7af_b.png
看out[44]的結果,代表了機器預測這120回的用詞習慣到底屬不屬於後40回(0為不屬於
,1為屬於)。
如果你看不懂上面的代碼,沒關係。我告訴你結果好了。
機器在學習以後告訴我,如果我把隨便一章的用詞習慣告訴它、但不告訴它到底是前80回
還是後40回,那麼機器有95%的把握能猜出它是不是後40回。
至此,我們可以很有信心地判斷它們的寫作風格不同。
那麼,問題來了,會不會因為是情節的需要所以導致寫作風格不同了呢?
情節不同會造成用詞習慣多大的差別?
好吧,那我再來做一個旁證。我把另外一部四大名著「三國演義」拿來分析,看看上部跟
下部的用詞習慣會不會有比較明顯的差別。
https://pic2.zhimg.com/83a849aba46a550bf5fb9094aa76b121_b.png
這個是三國演義的用詞習慣縮到三維以後的圖,紅色+代表前60部的用詞習慣,藍色o代表
後60部的用詞習慣。
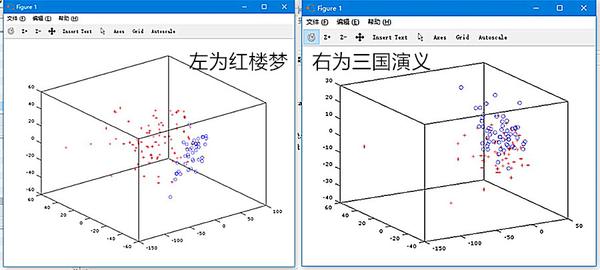
你可能會說,雖然中間交叉的地方比較多,但是還是可以看出來是有區分的。
可如果你比對一下跟紅樓夢的圖,你就會發現紅樓夢的差別會明顯得多。
https://pic2.zhimg.com/c3117edef7f9f8a05672c37fac4a6f59_b.jpg
(紅色+為紅樓夢前80回/三國前60回,藍色o紅樓夢後40回/三國後60回)
最後,用機器學習的方式來說,如果我把三國演義隨便一章的用詞習慣告訴它、但不告訴
它到底是前60回還是後60回,那麼機器有7成的把握猜對,這個準確度已經遠遠低於紅樓
夢的95%的預測水平。
所以,我們用「三國演義」這個旁證來分析,即便是因為情節需要導致的用詞習慣差別也
不應該這麼大。
所以,我們就更有信心說曹老先生沒有寫後40回了。
更多的機器學習有趣的玩法,我會在學習的過程中慢慢嘗試的。以上。
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 220.141.160.87
※ 文章網址: https://www.ptt.cc/bbs/Redology/M.1467790081.A.319.html
推 Ruthcat: 太強了! 07/06 16:10
推 Saddy: 有趣~~ 07/06 17:44
推 shaple: 太酷了 會想到這樣分析還真是厲害 好有趣的想法 07/07 09:49
推 taichungbear: 我FB轉這篇,不到八小時就33人轉貼 07/07 10:26
推 pandatom: 推 07/07 11:46
推 jimmyzhan614: 方法不夠嚴謹 至少也要cv反覆訓練才行 不過題材很 07/07 12:17
→ jimmyzhan614: 有趣 07/07 12:17
推 JKHOHS: 趕快推一下 不然人家以為我看不懂 07/07 13:00
推 disney82231: 政大統研所有一篇論文也是用數據分析後40是否是同一 07/07 13:31
→ disney82231: 個作者,結論好像也是非同一個作者~ 07/07 13:31
推 alan23273850: 推推 07/07 13:54
→ bauss: 杜協昌博士在四年前的數位典藏與數位人文研討會 07/07 14:02
→ bauss: 發過〈利用文本採礦探討《紅樓夢》的後四十回作者爭議〉 07/07 14:02
→ bauss: 利用斷詞跟詞頻分析的方法也幾乎一樣? 07/07 14:03
推 braveoscar: 請問你在訓練階段成效如何? 07/07 14:07
→ braveoscar: 訓練的好不好? 07/07 14:08
※ 發信站: 批踢踢實業坊(ptt.cc)
※ 轉錄者: nikolas (114.136.246.181), 07/07/2016 14:18:22
推 tiefblau: 老題目拉~ 07/07 14:35
推 darkgerm: 蠻有趣的XD 07/07 18:03
→ psion: 如果寫作時間超過十年 那就要再探討變異性 07/07 18:46
→ psion: 建議找一本寫了20年的名著測試一下前後對比 07/07 18:47
推 or0706555: 主成分分析的應用 07/09 23:37
→ or0706555: 我也是利用python來處理文字問題,不過我分析的是基因 07/09 23:38
→ or0706555: 組 07/09 23:38
推 mindscold: 那分析一下獵人會得到什麼…? 07/11 14:58
→ Neisseria: 要分析漫畫的話要先想辦法把圖轉為特徵 07/11 15:09
→ Neisseria: 我也不會轉,這也是一門專業 07/11 15:10
推 Sunal: 獵人太難了 可以先從死神入手... 07/13 15:23
推 juijuijuijui: 好玩~ 03/03 18:09