作者thefattiger (LawTea)
看板DataScience
標題[心得] 文章翻譯:為何DRL還行不通? Part1
時間Sat Sep 15 00:23:24 2018
Github好讀版連結
https://github.com/LilTwo/Article/issues/1
本文為
https://www.alexirpan.com/2018/02/14/rl-hard.html
的翻譯
這篇文章非常長,我預計分三到四個部分翻譯
講得都滿到位的,個人認為很值得花時間一看
有點出了幾個在DRL中常會遭運的困難
正文開始(以下的"我"代表的是原作者):
有一次在Facebook上,我說了下面這句話:
不管何時有人問我強化學習能否解決他們的問題,我都會告訴他們"不行"
我認為至少在70%的時候我是對的
因為某些理由,DRL被過分炒作
RL是個非常通用的方法,且原則上一個好的RL系統能在任何領域上都表現良好
而在過去一段時間DL也取得了很大的成功
因此將DL與RL結合起來是個再自然不過的事情
DRL是目前看起來最像強人工智慧(AGI)的方法之一,這吸引了無數的資金
但不幸地,現在它還很不成熟
我相信它具有成功的潛力,如果我不相信RL的話,我也不會研究它了
但現在依然存在非常多的問題,且很多是從根本上難以解決的
那些看起來完美的範例都將背後的血淚隱藏了起來
最近我看到有些人被DRL的一些成功案例矇騙了
他們一開始成功地用DRL解決了一些簡單的玩具問題
這些成功讓他們低估了DRL的困難,而後他們會經歷無數的失敗
直到他們知道如何設立合理的研究目標
這不是任何人的錯,更像是個系統性的問題
寫一個有關於成功案例的故事是很簡單的,但寫一個關於失敗案例的故事很難
失敗的案例是研究者實際上最常遇到的情況,並且它們也比成功的案例重要
在這篇文章剩下的部分,我會解釋為什麼DRL還不能很好地發揮作用,和那些成功案例
以及未來我預期DRL會如何地變得更可靠
寫這篇文章並不是要阻止人們投入這個領域
而是我相信如果人們能夠了解問題是什麼並取得共識,研究會更容易有進展
並且避免人們不斷重新發現其他人已經發現過的問題
我想要看到更多DRL的新研究,我想要更多人加入這個領域,我也想要人們了解他們會遇
到什麼
在文章繼續前,先講幾件事情
1.在這篇文章中我引用了一些paper,通常我是為了這些paper中具有啟發性的失敗案例而
引用它們,而略過裡面的成功案例
這並不代表我不喜歡這些paper,我喜歡它們,如果你有時間你也應該閱讀它們
2.我常常會交換使用RL和DRL這兩個詞,因為在最近RL通常指的是DRL
但我的批評針對的是DRL,而不是一般的RL
我引用的paper通常有一個具備深度網路的agent
雖然有些批評可能也適用於線性RL或表列式的RL,但我想這些缺點在較小的問題中是不存
在的
而DRL會紅起來是由於在大型、複雜及高維度的環境中,一個好的函數近似是需要的
這方面才是特別需要被點出來的
3.這篇文章的結構是從悲觀到樂觀,我知道文章有點長,但如果你在回應前花點時間把它
看完我會很感激的
在我們更進一步前,先提一些DRL失敗的點
DRL的取樣率非常差
最知名的DRL成功例子就屬Atari了,如同在那篇很有名的DQN paper裡,如果你將
Q-Learning與合理大小的神經網路結合起來
配合一些優化技巧,就能在幾款Atari遊戲裡達到人類甚至超越人類水平的表現
Atari遊戲的幀數是每秒60張,你能想像現在最先進的DQN算法要花多少禎數才能達到人類
水平嗎?
這個答案跟遊戲的種類有關,所以來看一下最近Deepmind的paper,Rainbow DQN
(Hessel et al, 2017).
這篇paper將各個增進DQN效能的技巧分開來研究,分析它們的優勢與欲解決的問題
並示範如何將這些技巧的優勢結合在一起,達到最好的效能
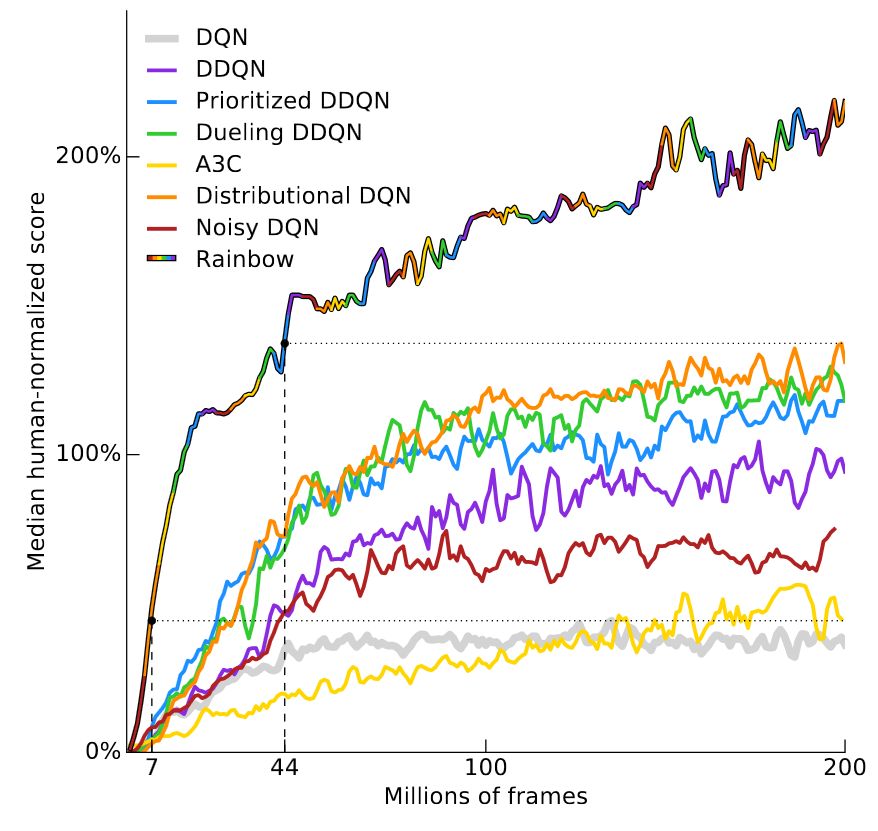
它可以在40/57款Atari遊戲中達到人類的水平,結果如下圖:
https://www.alexirpan.com/public/rl-hard/rainbow_dqn.png
y軸是"median human-normalized score",此分數計算方法是訓練57個DQN,每個DQN對應
一款遊戲
將DQN取得的分數以人類的表現為100%進行歸一化,然後取出中位數(在57款遊戲中)
RainbowDQN需要1800萬幀才達到100%,這對應的83小時的遊玩時間,還要加上訓練所花的
時間
而大多數時候,人類只要花幾分鐘就能上手一款遊戲
還要提醒你,1800萬幀已經很好了,前一個紀錄是Diributional DQN的7000萬禎,足足是
四倍
而原版的DQN即使訓練超過2億幀也達不到人類水平
RL要學好一個策略要花的樣本數通常都超乎你的想像
這個問題不是在Atari才存在,另一個有名的成功案例是MuJoCo,一個由MuJoCo模擬器所
定義的任務集
在這些任務中,輸入狀態通常是機器人各個關節的位置和速度,即使不用解決視覺的問題
(因為環境是模擬的)
這些任務也都要花10萬到1000萬步去學習,在這麼簡單的環境中這是非常驚人的量
DeepMind parkour paper出了以下的示範影片,策略是由64個worker訓練超過100個小時
所得到
paper中沒有明確說明worker代表什麼,但我假設是代表CPU
https://www.youtube.com/watch?v=hx_bgoTF7bs
這些成果很酷,當它剛出來時我很驚訝DRL可以達到如此成果
但同時,它們需要6400個CPU小時是令人沮喪的,我並不是預期它們應該需要更少的時間
而是DRL的取樣效率還是比實用水平高了好幾個數量級
這裡有一個很明顯的反駁論點:如果我們忽略取樣效率的?
有很多的環境下樣本是非常好取得的,例如遊戲
但不幸地是,現實中的環境大多數不是如此
如果你只在乎最後的成果,多數問題都能夠用其他方法解決並得到更好的結果
當你在找某個研究問題的解決方案時,通常都要在幾個目標間做取捨
你可以找到一個很好的解決方法,抑或是貢獻出一些很好的研究成果
最好的研究問題是那些你既可以找到好的解決方案同時也能貢獻好的研究成果
但找到這種問題是很難的
當你只關心效能時,DRL通常沒那麼好,它常輸給其他的方法
下面是一個MuJoCo的機器人,使用online trajectory optimization控制
正確的動作是在近乎即時、線上且沒有離線訓練的情況下被計算出來的
而且是跑在2012年的硬體上
https://www.youtube.com/watch?v=uRVAX_sFT24
我想這些行為跟parkour paper比起來是很好的,這兩個有什麼不一樣?
不一樣的點在於Tassa等人用的是model predictive control,能對真實的模型做出
planning
Model-free的RL沒有做這種planning,所以它難得多
另一方面,如果對模型做planning幫助如此之大,為什麼還要訓練一個華而不實的RL策略
呢?
類似於上個例子,你可以輕易地用現成的MCTS超越DQN,底下的數字來自Guo et al,
NIPS 2014
他們比較了DQN與UCT的在Atari遊戲中取得的分數(UCT是現在MCTS的標準版本)
再一次強調,這個比較並不公平,因為DQN沒有做搜索,MCTS則對真實的模型做了搜索
不過有時候你並不關心公平與否,你只想要演算法能夠成功地運作
強化學習理論上可以在任何事情上運作,包含那些無法得知環境模型的情況
但是這種通用性是有代價的:你很難取得到對特定問題的學習有幫助的資訊,這使你必須
取得非常大量的樣本
經驗法則是:除了那些特定的案例,針對該領域本身的演算法都能夠做得比RL更快更好
如果你使用DRL是為了研究DRL本身,那這並不重要,但當我將RL與其它幾乎任何演算法比
較時都相當沮喪
我喜歡AlphaGO的其中一個理由是它毫無疑問的是DRL的成功,這種例子非常少見
這讓我很難與外行人解釋為什麼我的問題是困難且有趣的,因為他們通常沒有經驗去了解
DRL難在哪
人們想像DRL能做到的事與它們實際能做到的事之間有一道很大的落差
我現在這在研究機器人,想一下當人們提到機器人時會想到的第一間公司:Boston
Dynamics
https://www.youtube.com/watch?v=fRj34o4hN4I
很多人以為這是用RL達成,但並不是
如果你去看他們的paper,你會發現paper提到 time-varying LQR, QP solvers,
optimization
換言之:傳統的機器人控制方法,當你正確使用這些方法時它們可以表現的很好
RL通常需要一個獎勵函數B
RL假設獎勵函數存在,通常是被給定的,或者由人工設計並在訓練時固定
我說"通常"是因為有例外,如inverse RL,但大部分的RL方法都需要獎勵函數
為了讓RL正確地執行,獎勵函數需要精準地描述你的任務,請注意,是"精準地"
RL有一個很惱人的傾向是overfit你的獎勵,導致那些你沒有預期的事情發生
這就是為什麼Atari是一個很好的參考案例,不只是因為它很容易取得很多樣本
也是因為在所有遊戲裡目標都是取得盡可能多的分數,所以你不需要擔心怎麼設計獎勵函
數
而且你知道所有人都有一樣的獎勵函數
這也是為什麼MuJoco的任務是在這個領域如此地流行
因為它們是在模擬環境中執行,你對於物體的狀態有完整的理解
這讓獎勵函數的設計簡單了很多
在"Reacher"任務中,要控制一個由兩部分組成的手臂,手臂連接到中央的點
此任務的目的是要移動手臂的端點到目標的位置,下面的影片是一個成功學習的策略
https://www.youtube.com/watch?v=BkhSKqc8vSA
因為所有的位置都是已知的,獎勵可以被定義為手臂端點的目標的距離,加上一些控制成
本的損失
原則上在真實世界中也可以這麼做,只要你有夠多的感測器能夠精準地測量環境中的位置
但是在某些系統中合理的獎勵是很難定義的
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 58.114.212.150
※ 文章網址: https://www.ptt.cc/bbs/DataScience/M.1536942208.A.83D.html
推 sma1033: 唉唷不錯喔 09/15 05:37
→ sma1033: 這篇文章點到很多RL研究會碰到的問題,我覺得很值得看 09/15 05:38
推 st1009: 推推 如果方便的話,把內容貼到PTT上吧,ctrl+e可以編輯文 09/15 12:02
→ st1009: 章 09/15 12:02
※ 編輯: thefattiger (58.114.212.150), 09/17/2018 23:04:27
推 a78998042a: 推推 09/18 21:53
推 uloyoy: 感覺DRL會紅是因為它對domain knowledge的要求較低 09/19 11:13
推 sr29: 我一直以為DRL的reward function對domain knowledge還是很有 09/19 23:47
→ sr29: 要求的,直到我看了hindsight experience replay的論文... 09/19 23:48
→ thefattiger: 之前試過HER的效果沒想像中的好 09/20 11:24
→ thefattiger: goal不是那麼好設計 09/20 11:25
推 steven95421: 推 11/23 02:18