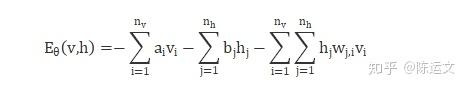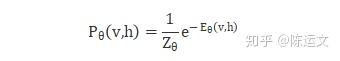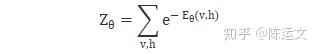作者loser113 (洨大魯蛇ㄍ)
看板Physics
標題[問題] 機器學習RBM模型中的 能量函數解釋
時間Sun Apr 19 10:50:03 2020
參考對岸之乎介紹
https://zhuanlan.zhihu.com/p/40120848
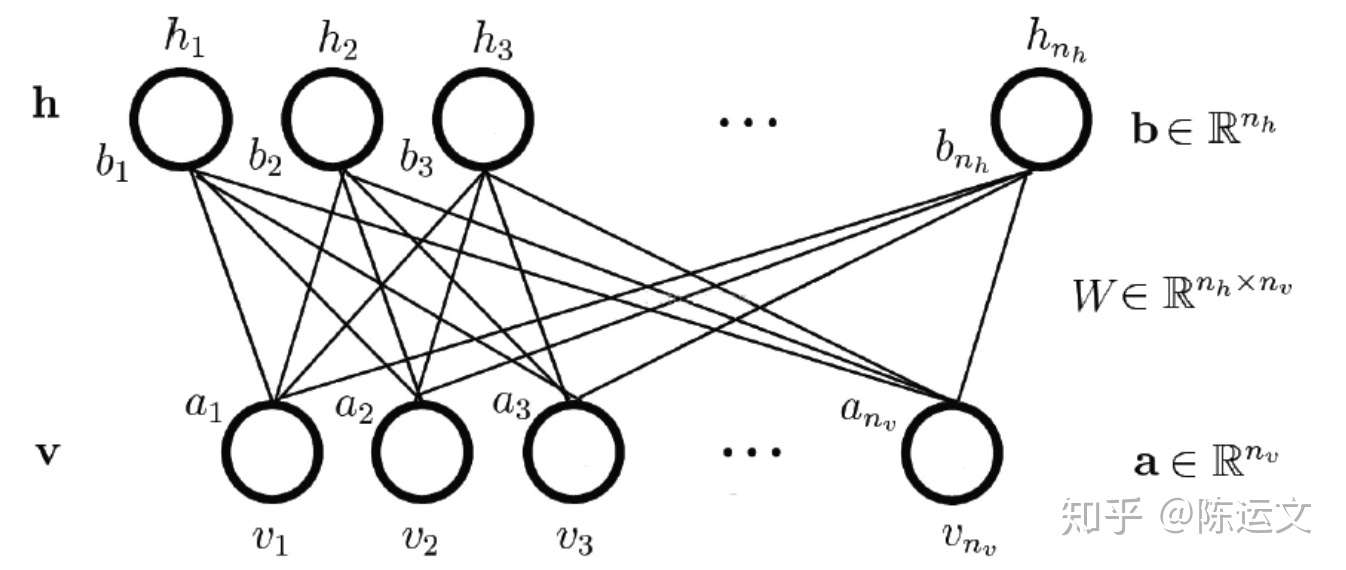
模型概念圖
https://pic3.zhimg.com/80/v2-b81b786ae6eb1bbaa1c04c7b3963e8ea_1440w.jpg
目前在學RBM裡面用了一個能量函數 ( nergy function)
https://pic1.zhimg.com/80/v2-8f783076cd101380913929745026c7e0_1440w.jpg
利用物理概念但是 還是不太懂設置這函數的用意
目前已獲得的訊息是能量越低越穩定
機器學習模型追求是準確度
裡面演算法運算 是找到某個參數最大概似函數最大值 (這邊數學部分就不多做解釋)
使得聯合函數最大
https://pic2.zhimg.com/80/v2-e0db53e5ff23cd01b8a8f11f965fb0e9_1440w.jpg
其中
https://pic3.zhimg.com/80/v2-148857ea03b7564bbf5bc500df86568a_1440w.jpg
理論上是每個P都相等機率相乘會最大 那不太懂這邊追求每個P相近
用物理怎麼解釋節點(每組V到模型的差異相近?)
或者更直接一點 怎麼解釋追求 每個P相近 對於模型準確度有甚麼關係
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 27.242.67.62 (臺灣)
※ 文章網址: https://www.ptt.cc/bbs/Physics/M.1587264606.A.16C.html
→ CY2018: 網站點進去很黑所以沒看,印象中在某篇算多體系統的paper 04/20 10:08
→ CY2018: 中這裡的P是拿來做Monte Carlo sampling,sample 出很多 04/20 10:08
→ CY2018: 個system configuration後,用這些basis算出一個ground st 04/20 10:08
→ CY2018: ate energy,再得出要最小化ground state energy的weight 04/20 10:08
→ CY2018: gradient,得出下一組RBM參數,再做一樣的事,直到最後會 04/20 10:08
→ CY2018: 收斂到一組參數使得ground state energy最小。 04/20 10:08
→ CY2018: 所以看你的目標函數是什麼,RBM主要作用在產生sample的機 04/20 10:12
→ CY2018: 率那邊,每次更新參數後機率分佈會有些改變,最後收斂到會 04/20 10:12
→ CY2018: 算出你目標函數極值的參數,大概是這樣。 04/20 10:12
推 NTUmaki: 感覺跟統計熱力有點像 04/25 10:39