推 BBKOX : 後面就智能機器啊,AI女友 12/12 10:01
推 tsubasawolfy: 除了成績你還要看他的每次對話成本,那個才是商業 12/12 10:04
→ tsubasawolfy: 核心。Gemini3普通版”目前”還是在甜蜜點上。但極 12/12 10:04
→ tsubasawolfy: 限版輸慘了,77美vs15美。 12/12 10:04
大大說得真好 ultra會員太貴了
不過企業跟研究用戶應該願意付錢吧?
不知道之後統計出來美國企業的採用率會不會改變
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:08:26
推 doubi : 企業採用 Workspace 其實也算買了半套 Gemini 12/12 10:10
→ doubi : 確實 API 層面 OpenAI 先手優勢依舊相當明顯 12/12 10:10
→ doubi : 但是 OpenAI 其實會去關心公司的使用量太低問題, 12/12 10:11
→ doubi : 他們很有壓力 12/12 10:11
根據紐約時報十一月底的報導
OPEN AI十月的時候公司內部就發布橙色代碼警報了
(我沒寫錯 不是前陣子那個紅色代碼)
================
10月份,負責ChatGPT的特利先生向全體員工發布了一項緊急通知,宣布進入「橙色警報
」狀態。據四位能夠訪問OpenAI Slack的員工透露,特利先生在通知中寫道,OpenAI正面
臨「前所未有的巨大競爭壓力」。他表示,這款更安全的聊天機器人新版本無法與用戶建
立聯繫。
該通知附帶一份備忘錄,其中列出了各項目標。其中一項目標是在年底前將每日活躍用戶
數提高5%。
================
看來他們是真的有在注意用戶動態 而且很敏感
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:15:25
推 chigo520 : 比較好奇這些ai的客群是要往高端專業還是普羅大眾? 12/12 10:11
→ chigo520 : 普羅大眾比較好賺錢吧? 12/12 10:11
兩者都很重要 但是應該會把重點放在企業用戶?
11/11華爾街日報報導評估 Claude的公司Anthropic會比OPEN AI較早開獲利
分析的原因之一是因為Anthropic重視企業用戶 而且API高額收費
→ doubi : Google 一旦接入公司生態,簡直就變成基礎建設一樣 12/12 10:11
所以OPEN AI才會發布紅色代碼警戒?不知道市場會怎麼看GPT5.2的表現
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:21:12
推 shadow0326 : M365已經把copilot變成基礎建設了,但是不太好用 12/12 10:17
→ shadow0326 : Google不知道能不能做得更好 12/12 10:17
→ ppit : 跳來跳去也是要成本的,如果差異沒拉開不會馬上跳 12/12 10:18
推 as6633208 : m365 copilot 就是一個例子,生態系很廣啊,但是不 12/12 10:19
→ as6633208 : 好用,沒屌用,模型答案好用答案準確才是重點 12/12 10:19
推 deathoflove : M軟就是compliance強 在規範比較嚴格的產業會用 12/12 10:21
推 kakar0to : 模型在測驗ARC-AGI-2 會不會是用背答案的方式在答題 12/12 10:21
→ kakar0to : 畢竟考題是有限的 總不可能無限的生出沒有看過的考 12/12 10:22
→ kakar0to : 題吧? 12/12 10:22
你這問題讚 ARC-AGI-1就是因為有公開題庫可以背答案
所以他們才要開發ARC-AGI-2 每一個正式測驗的題目都是新出的
我記得官網好像有在徵求願意幫忙設計題目的人
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:24:17
推 as6633208 : 那就厲害了,用過去訓練的資料,湧現算出來接近的答 12/12 10:23
→ as6633208 : 案,人工智慧 12/12 10:23
聽說現在是用強AI或教師AI設計ARC-AGI-2的題目給模型鍛鍊
沒有考古題 所以高階模型自己教自家模型怎麼模擬臨機應變的推理方式
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:27:34
→ bnn : 你人類也是考試背多分 然後才開始訓練思考 12/12 10:26
→ bnn : AI的好處甚至是背多分他還不像你人類不常用又忘記了 12/12 10:27
模型知識常識(晶體智力)很強大
常看到一些網友嘲笑LLM是笨蛋 那些人是拿一些人類靠計算機或筆算的方式去考AI
但忽略了AI沒有眼睛 ARC-AGI-2就是在鍛鍊模擬的視覺推理能力
這項如果超過大多數人可能那些笑LLM是笨蛋的再也笑不出來
比喻來說這就好像一個人流體智力到達普通程度 晶體智力卻破表耶 超可怕
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:30:27
推 seemoon2000 : LLM解題超越人類只是時間問題 會笑的人只是不願面對 12/12 10:33
推 fanntasy : 圖裡面gem3pro沒有50幾分的點呀? 12/12 10:55
→ fanntasy : 只有30跟45(45還要耗100元@@? 12/12 10:56
感謝提醒
我沒貼錯但貼成沒展開的
那張GPT5.2 Pro (High)右邊的白色三角型是Gemini 3.0 Pro(Refine)
https://i.imgur.com/N6V3Kkv.png
右下方綠色三角形是Gemini 3.0 Pro Deep Think
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 10:59:23
推 sdbb : 謝謝 12/12 10:59
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:00:21
推 bettybuy : Ger丟判決書給他整理,大部分都是正確的,GPT不知道 12/12 11:03
→ bettybuy : 準確率如何,之前法律文件類整理跟使一樣 12/12 11:03
→ bettybuy : /Gemini 12/12 11:04
推 pippenjr : 準備噴出 12/12 11:05
推 ltflame : 後面你就不用工作了,提前達到馬斯克的願景 12/12 11:06
→ pippenjr : gpt應該會比gemini好 12/12 11:06
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:18:44
→ ur260 : 要去哪裡玩測驗? 12/12 11:35
https://arcprize.org/arc-agi/2/
頁面下方有三種測驗 分別點TRY THIS TASK可以玩
模型沒有眼睛 所以他們是這樣推的
例如:
(1,1) black (1,2) red (1,3) blue....
把20X20的範例題三題讀取分別的前後變化 找出規則
然後看施測考題 模擬推理出變化後是怎樣的
這全程沒有眼睛可以看 只能靠文字推 很容易出錯 錯一格就是全錯
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:45:04
推 as6633208 : 媽耶,我玩下來感覺我好像不如AI欸 12/12 11:43
拍拍 我覺得這些題目需要非~~~常細心又認真又花時間
問題就是很容易因為粗心出錯 錯一格就就是錯 沒有商量餘地
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 11:47:41
推 junior020486: Google這麼快就下神壇了 12/12 11:48
推 ezorttc : 我都退訂了 12/12 11:56
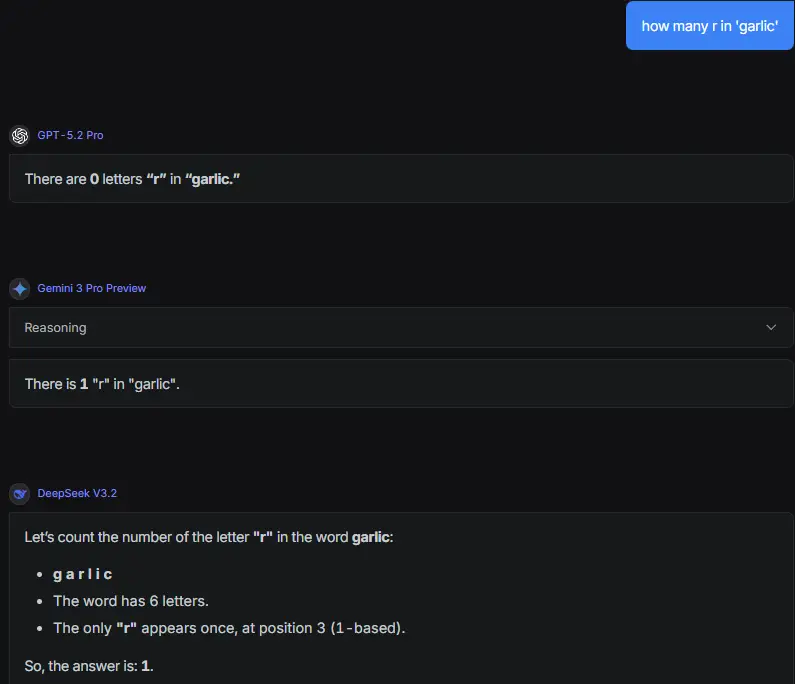
→ h0103661 : pro要價128美金/M結果連字母都不會數 12/12 12:06
推 h0103661 : reddit現在up最高的文章就是笑他不會數大蒜xD 12/12 12:09
我用不登入頁面問有答對耶
https://i.imgur.com/PX4oZ1F.png
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 12:16:02
推 h0103661 : 不登入是5.1,網頁版5.2左上會顯示而且目前只有付 12/12 12:16
→ h0103661 : 費用戶能用,可以去singularity板看一堆人都是 12/12 12:16
感謝分享 原來是5.2才有的現象
GPT5.1的說明: https://i.imgur.com/WhAIS77.png
意思好像是說因為太聰明所以分類器容易疏忽而誤判 分配給錯誤的模型導致答錯
如果是故意選Pro回答那個問題 我覺得可能是故意要看高階推理模型出糗
Gemini 3.0 pro對GPT5.2 Pro出錯的說明:
網友特地選 Pro,就是因為知道 Pro 是經過**「特化訓練(Specialized)」的。而在機
器學習中,越是特化的模型,通常在非專長領域的表現就越容易出現「災難性遺忘」**。
====
Pro 本身的權重,是為了「專業語義工作」優化的(根據 PDF 第 1 頁的定位)。為了在
專業任務上表現穩定(低變異),它犧牲了對字面細節的敏感度(高偏差)。
所以當 Pro 接到任務時,受限於它自身的權重設定(Weights),它看不見字母,只能
用猜的,結果猜錯。
====
如果一開始就選Auto讓分類器自動選派 那還轉給Pro回答就真的很尷尬
如果是故意不用Auto 選用Pro回答這個問題 這算是在找碴
因為權重不一樣 不能說Pro答不出來就代表"新模型GPT5.2連這題都不會"
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 12:17:21
推 losage : 老闆:剩下來的時間是為了加重各位的工作量 12/12 12:27
→ strlen : 人早就不如AI了 賽道不同不用比了 12/12 13:11
※ 編輯: LoveSports (64.31.11.7 日本), 12/12/2025 13:40:31
推 a3456777 : 覺得是樹大招風,現在好像是批評gpt才有流量,同樣 12/12 15:13
→ a3456777 : 的問題我問gpt是對的,gemini是錯的,但我也不會因 12/12 15:13
→ a3456777 : 為這一件事去說誰好誰壞 12/12 15:13
→ fitenessboyz: GPU一定還是比較香的啦 12/12 15:31
推 mp5k6 : 沒有色色用途 我可是不買的喔 12/12 16:11